The Oracle (3)
Yesterday was the end of round 1 for the group stage \(-\) this means that all 32 teams have played at least once (in fact, Brazil and Mexico have now played twice). So, it was time for us to update our model including a new measure of “current form” for each of the team.
We based this on the previous value (which as explained here was estimated using a synthesis of published odds against each of the teams, suitably rescaled to produce a score in [0;1], with values close to 0 indicating a weak/not in form team). These were modified accounting for the result of the first game played in the World Cup.
In particular, we computed the increase (decrease) in the original score weighting by the estimated probability of actually getting the observed result \(-\) I think this makes sense: a strong team beating a weak opponent will probably increase in their current form (eg because this will naturally boost their confidence and get them closer to qualifying for the next round). But this increase will probably be marginal, in comparison to a weak team surprisingly beating one of the favourites.
By weighing the updated scores we should get a better quantification of the current strength of each team. Also, by using some form of average including the starting value, we are not overly moved by just one result. So, for example, Spain do decrease their “form score” from 0.93 to 0.68 by virtue of their not very likely (and yet observed!) thorough defeat against the Netherlands; but without accounting for the very high original score, the updated one would have been 0.42 \(-\) quite lower.
So, we can re-run the model with these two extra features:
- the observed results for games 1-17 (including Brazil-Mexico);
- the updated form score for each of the teams
and use the new estimated values to predict the results of the next round of games (18-32). The graphs below show contours of the estimated joint predictive distributions of the scored goals. I’ve also included the 45 degrees line \(-\) that would be where the draws occur, so if the distribution is effectively bisected by the line, a draw is the most likely outcome. If, on the other hand the line does not divide the distribution in two kind-of-equal halves, then one of the two teams have a higher chance of winning (as they are more likely to score more goals \(-\) see for example the first plot for Netherlands-Australia).

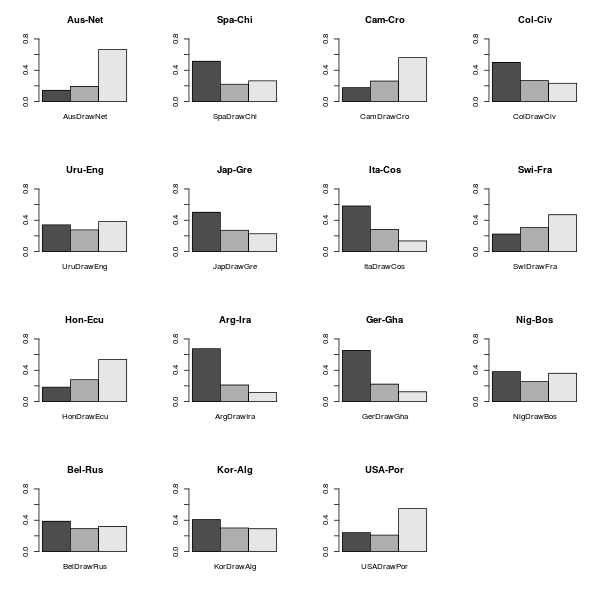
These analyses translate into the estimation of the (model-based) chance of winning/drawing/losing the games for the two opponents. The situation seems a bit more clear-cut than it was for some of the games in round 1 \(-\) England seems to be involved again in one of the closest games, although this time they seem to have an edge on Uruguay.
Finally, it probably now starts to make a bit more sense to think in terms of estimated chance of progressing through to the next stage of the competition. Assuming that the current form won’t change from round 2 to round 3 (which again is not necessarily the most appropriate assumption), these are the estimated probabilities of progressing to the knockout stage.
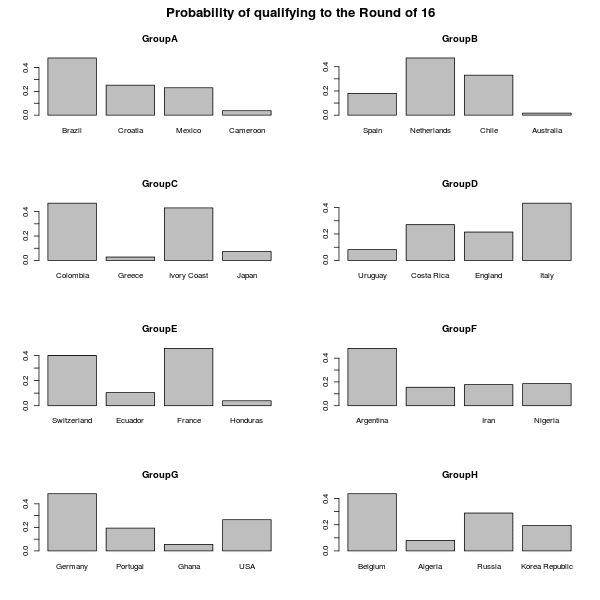
As is obvious, these are quite different from the ones displayed here which were calculated based on “current form” before the World Cup was even played. More importantly, teams have now won/lost, which is of course accounted for in this analysis.
In Group B, The Netherlands are now big favourites to go through, which Chile slightly better off than Spain (but of course, things may change later today when these two meet). Italy are now hot favourites in Group D, where formerly most-likely-to-go-through Uruguay are left with a small chance of qualifying, after losing to low-rated Costa Rica. Portugal have also taken a big hit in terms of their chances of going through (that’s Group G), after being heavily defeated by Germany, who are now clear favourites.
We’ll keep updating the model and reporting (perhaps in more details) on how well we’d done in predicting the results for round 1 (I haven’t had much time to do this, yet, but I will do in the next few days).